İçindekiler
Ceph Mimarisi ve Ceph Üzerinde Veri Yerleşimi
Bu yazıda Ceph çalışma mantığının daha iyi anlaşılabilmesi için Ceph mimarisi ve örneklerle Ceph üzerinde veri yerleşimi konuları ele alınacaktır. Eğer Ceph ile ilgili kısaca bilgi edinmek isterseniz daha önce yayınladığım “ilk Bakışta Ceph” isimli yazıya göz atmanızı öneririm.
Ceph Mimarisi
Ceph daha önce özetlendiği üzere nesne tabanlı ve blok depolama ile dosya sistemi türündeki depolama ortamlarının tamamını bir arada sunan ve bu amaçla 5 temel bileşenden oluşan açık kaynak kodlu bir depolama çözümüdür. Bu 5 bileşen aşağıda açıklanmıştır:
- Ceph OSD (Object Storage Daemon): OSD bileşenleri veriyi nesne halinde tutmakla yükümlüdür. Verinin kopyalar halinde (replikasyon) tutulmasını yönetir. Disk ekleme/çıkarma işlemleri sonrasında verinin depolama ortamı üzerinde yeniden yapılandırılarak gerekli kopyaların oluşturulmasını ve diskler üzerinde dengeli olarak dağıtılmasını sağlar. Ayrıca monitör sunucularına disklerin durumu ile ilgili bilgi sağlar. Önerilen yapıda her disk için ayrı bir OSD kullanılması önemli konulardan birisidir.
- Ceph MON (Monitor): Monitör bileşenleri tüm depolama ortamının sağlıklı çalışmasını takip amacıyla haritasını tutar. MAP ismi verilen bu haritalar arasında OSD Map, Monitor Map, PG Map ve CRUSH Map bulunur. Monitör bileşenleri diğer tüm bileşenlerden durum bilgilerini alarak haritayı çıkarır ve bunu diğer monitör ve OSD bileşenleri ile paylaşır. Ceph istemcileri bir okuma veya yazma yapacağı zaman yazacağı OSD ve PG’leri belirledikten sonra bu OSD’lerin çalışır durumda olup olmadığına bakar. İlk belirlenen erişilebilir durumda değilse duruma göre 2. veya 3. OSD kullanılır. Burada belirlenen OSD sayısı replikasyon sayısına bağlıdır.
- Ceph RGW (Rados Gateway): RGW, Ceph’in doğrudan nesne tabanlı depolama ortamına erişmeye olanak veren API servisini sağlayan bileşendir. Bu API Amazon S3 ve OpenStack Swift API ile uyumludur.
- Ceph RBD (Rados Block Device): RBD, Ceph’in nesne tabanlı depolama altyapısı üzerinde çalışan ve sanal sunucular, fiziksel sunucular ve diğer istemcilere blok tabanlı depolama sağlayan katmanıdır. OpenStack ve CloudStack desteği bulunur. Ticari çözümlerin sunduğu snapshot, thin-provisioning ve compression gibi özellikleri destekler.
- Ceph FS (File System): Ceph’in nesne tabanlı depolama altyapısını kullanarak istemcilere POSIX uyumlu dosya sistemi vermesini sağlayan katmanıdır. Linux kernel üzerinde CephFS mount etmek üzere hali hazırda destek bulunduğu gibi alternatif olarak FUSE kullanılarak da mount işlemi yapılabilir. Diğer bileşenlerin aksine CephFS çalışmak için bir metadata sunucusuna ihtiyaç duyar.
Aşağıdaki resimde bu bileşenler gösterilmekte olup monitör sunucuları ve OSD sunucuları ile eğer ihtiyaç duyuluyorsa RGW sunucuları ve metadata sunucuları eklenerek aşağıdaki servisler sağlanabilir.
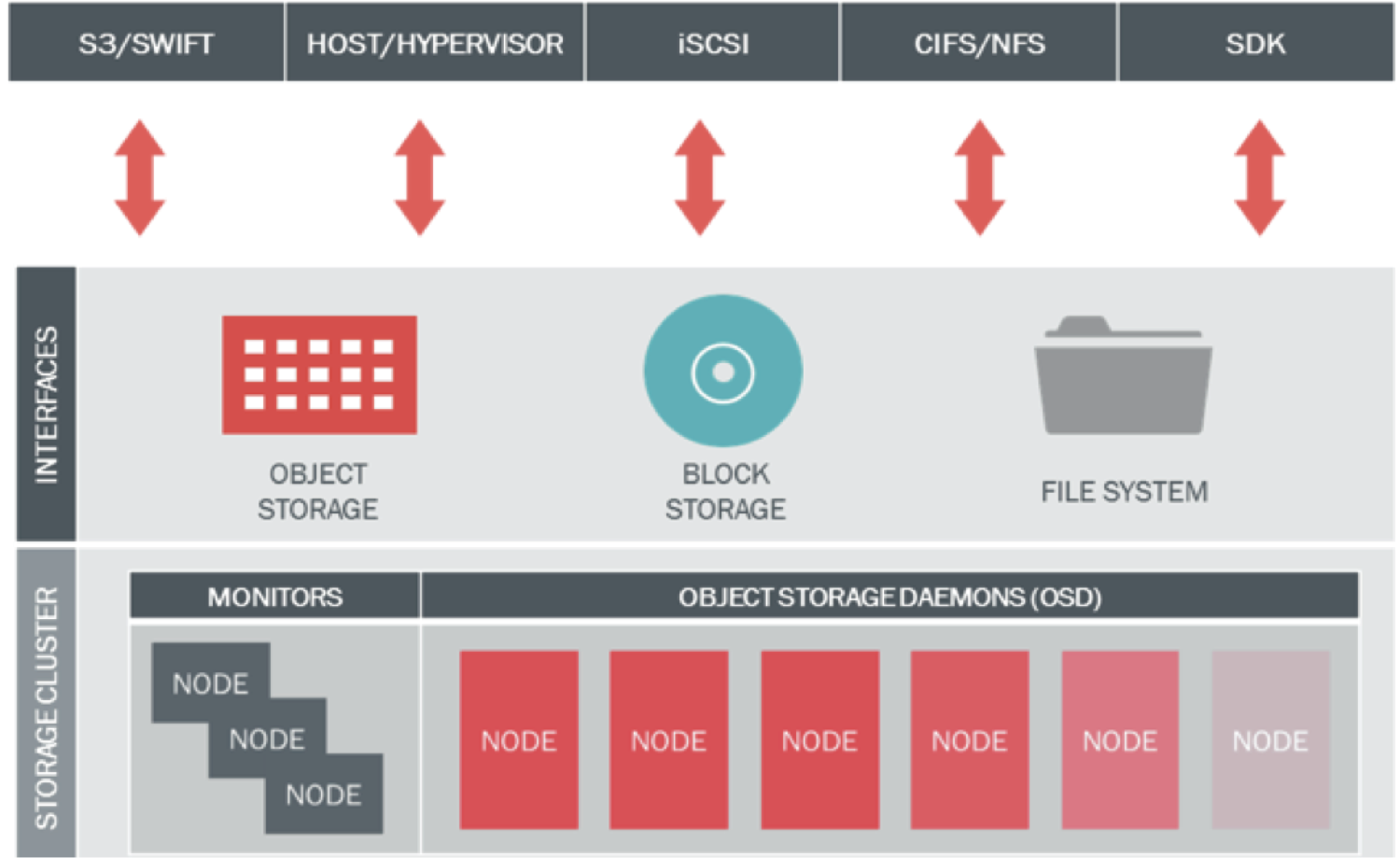 (Kaynak : www.ceph.com)
(Kaynak : www.ceph.com)
OSD katmanını biraz daha anlaşılabilir hale getirmek için aşağıdaki resimdeki yapıya dikkat çekilebilir. Depolamanın yapıldığı OSD sunucuları üzerinde işletim sisteminin çalıştığı bir disk ya da disk grubu bulunur. Bu resmin en solunda bulunan ilk sutünda görülmektedir. Alt katmandaki disk ext3, ext4, xfs gibi bir dosya sistemi ile formatlanarak üzerine işletim sistemi kurulur. Bu tüm sunuculardaki klasik kullanım şeklidir. Yanındaki sütunda sarı renk ile gösterilen journal ise OSD servislerinde çalışan mekanik disklere (SAS, SATA veya NL-SAS gibi) önbellek (cache) olarak bağlanmak üzere tasarlanan ve SSD üzerinde çalışan bir yapıdır. SSD disklerin yüksek yazma hızı ve IOPS performansından faydalanılarak yapılan yazma isteklerini karşılayarak sıralı (sequential) hale getirir. Bu disk üzerinde belirlenen süre boyunca önbelleklenen veri sıralı halde daha hızlı bir şekilde diske yazılır, böylece okunurken de sıralı biçimde daha hızlı okunur. OSD servislerine bağlı mekanik diskler ise resmin sağında yer alan ve kesikli çizgi ile çevrelenen alanda gösterilmektedir. Burada da diskler ext4, xfs veya btrfs gibi dosya sistemi ile formatlanarak OSD servislerine bağlanır. OSD servisi veriyi sunucu üzerine OSD servisleri ile mount edilen bu disklere nesneler halinde yazar.
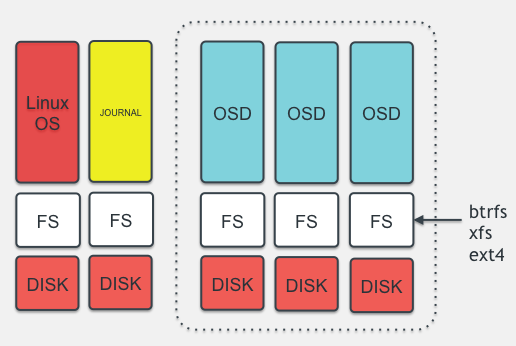
Ceph Üzerinde Veri Yerleşimi
Ceph üzerindeki veri yerleşimini anlamak için önce Ceph tarafından kullanılan bazı temel yapı taşlarını anlamak gerekmektedir. Bunlardan bu aşamada gerekli olanlar aşağıda özetlenmiştir:
Veri Havuzu (Pool): Verileri birbirinden mantıksal olarak ayırmak üzere tasarlanmış, içerisinde imajları barındıran üst seviye bileşenlerdir. Her veri havuzu oluşturulurken veri miktarı ile doğru orantılı olarak belirlenen yerleşim grubu sayısı ile birlikte oluşturulur.
İmajlar (Images): Veri havuzlarının içerisinde yer alan ve blok depolama kullanmak üzere kullanılan bileşenlerdir.
Yerleşim Grubu (Placement Group-PG): Verileri gruplamak üzere OSD ve veri havuzları arasında kullanılan yapı taşlarıdır. OSD başına PG ortalamasının 100-150 civarı olması önerilmektedir. OSD başına PG sayısının 300’ü geçmesi sakıncalı bulunmaktadır.
Kural Grubu (Ruleset): Ceph’in kullandığı CRUSH algoritmasına ait haritanın (CRUSH Map) veriyi özel tanımlar ile hiyerarşik yapıda dağıtmasına izin vermek için kullandığı kurallardır. Varsayılan olarak hiyerarşik yapıda Region/DC/Room/Pod/PDU/Row/Rack/Chassis/Host/OSD olarak tanımlanan sırada örneğin farklı disk tiplerinden farklı veri havuzları oluşturarak (SSD’ler için ayrı, SAS’lar için ayrı, SATA’lar için ayrı) bu kurallar vasıtasıyla ilgili veri havuzlarının ilgili disk gruplarını kullanması sağlanır.
Buna göre herhangi bir istemci bir veri yazma talebinde bulunduğu zaman aşağıdaki resimdeki sıra ile yazılacak alan belirlenir ve replika sayısına göre kopya çıkarılır.
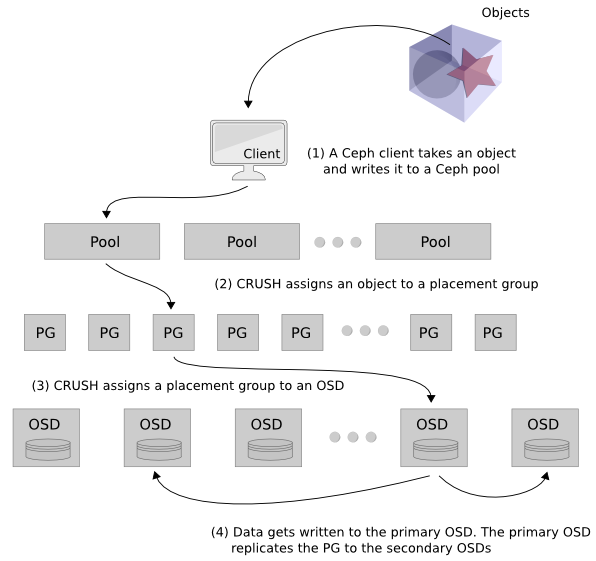
- Öncelikle istemci tarafından yazılacak veri belirlenir ve Ceph üzerinde bulunan bir veri havuzuna yazma talebi yapılır.
- CRUSH algoritması çalıştırılarak istemcinin yazması gereken PG ataması yapılır. Bu esnada herhangi bir metadata sunucusuna veya başka bir lookup tablosuna bakılmaz.
- CRUSH algoritması ayrıca kullanılacak PG’yi bir OSD ile eşler. Böylece istemci veriyi birincil olarak belirlenen PG dolayısıyla OSD üzerine yazar.
- CRUSH tarafından belirlenen birincil OSD’ye yazma işlemi tamamlanınca, verinin kopyası replika sayısına bağlı olarak diğer OSD’lere yazılır. Örneğin replika sayısı 3 ise birincil OSD’ye yazılan veri 2 ayrı OSD’ye daha kopyalanır. Bu OSD’ler varsayılan CRUSH map ayarlarında farklı sunucular üzerinde olacak şekilde ayarlanmıştır. Tüm kopyalar yazıldıktan sonra istemciye yazma işleminin başarılı olduğu bilgisi verilir.
CRUSH Algoritması
CRUSH (Controlled Replication Under Scalable Hashing), Ceph üzerinde verinin nereye yazılıp nereden okunacağını bir hesaplama yaparak belirleyen ve hem istemci hem de sunucularda bulunan, bu sayede veri lokasyonu için ikinci bir işlem gerektirmeyen bir algoritmadır. Daha önce bahsedildiği gibi Ceph bu yaklaşım sayesinde yüksek ölçeklere rahatlıkla çıkabilmektedir.
Aslında basite indirgenecek olursa hash işlemine benzer bir hesaplama ile verinin yerleşimi hesaplanır. Bunu bir örnek ile açıklayalım. Elimizdeki “huseyin” nesnesini “cotuk” isimli veri havuzuna yazmak isteyelim. “Cotuk” isimli veri havuzunun kimliği (ID) 5 olsun. Depolama ünitemizde de toplam 32768 PG olsun. Bu durumda:
- “Huseyin” isimli nesnenin hash’i alınır. hash(‘huseyin’) = 0x894513ce
- PG sayısı ile modulo işlemine tabi tutulur: 0x894513ce mod 32768 = 0x13CE
- Yazılacak veri havuzunun kimliği alınır: 5
- Bulunan iki değer birleştirilerek PG elde edilir. 5.13CE
Ceph bu placement group (PG)’yi kullanarak aktif küme haritası (cluster map) ve kuralları dahil ederek kullanılacak OSD’leri hesaplar.
CRUSH(‘5.13CE’) = [ 7, 26, 16 ]
Burada OSD.7 birincil, OSD.26 ikincil ve OSD.16 üçüncül OSD olarak belirlenmiş olur. Daha önce bahsedildiği gibi buradaki sayı replika sayısına bağlıdır.
Arka planda algortima, depolama ünitesinin nasıl organize edildiğini (cihaz lokasyonları, hiyerarşik dizilişleri, v.b.) bilmesi gerekir. Tüm bu tanımlar CRUSH map ile yapılır.
CRUSH map rolü ve sorumlulukları aşağıdaki gibidir:
- Her hiyerarşik yapı için tanımlanan kurallarla birlikte Ceph’in veriyi nasıl saklayacağını belirler.
- Çok aşamalı olabileceği gibi en az bir düğüm ve yaprak hiyerarşisine sahip olmalıdır.
- Hiyerarşideki her düğüm sepet (bucket) olarak adlandırılır ve her sepetin bir tipi vardır.
- Verileri tutan nesneler disklere verilebilecek ağırlıklara disklere dağıtılır.
- İhtiyaca göre istenilen esneklikte hiyerarşik yapı tanımlanabilir. Tek kısıt en alttaki yaprak ismi verilen düğümler OSD’leri temsil etmelidir. Ayrıca her yaprak düğüm bir sunucuya ya da başka bir tipteki sepete bağlı olmalıdır.
Örnek bir CRUSH map hiyerarşisi aşağıda gösterilmiştir.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -7 7.07993 root ssds -8 1.41599 host ceph01-ssd 45 1.41599 osd.45 up 1.00000 1.00000 -9 1.41599 host ceph02-ssd 46 1.41599 osd.46 up 1.00000 1.00000 -10 1.41599 host ceph03-ssd 47 1.41599 osd.47 up 1.00000 1.00000 -11 1.41599 host ceph04-ssd 48 1.41599 osd.48 up 1.00000 1.00000 -12 1.41599 host ceph05-ssd 49 1.41599 osd.49 up 1.00000 1.00000 -1 245.59483 root hdds -2 49.10500 host ceph01-hdd 0 5.45599 osd.0 up 1.00000 1.00000 1 5.45599 osd.1 up 1.00000 1.00000 2 5.45599 osd.2 up 1.00000 1.00000 3 5.45599 osd.3 up 1.00000 1.00000 4 5.45599 osd.4 up 1.00000 1.00000 5 5.45599 osd.5 up 1.00000 1.00000 6 5.45599 osd.6 up 1.00000 1.00000 7 5.45599 osd.7 up 1.00000 1.00000 8 5.45599 osd.8 up 1.00000 1.00000 -3 49.10500 host ceph02-hdd 9 5.45599 osd.9 up 1.00000 1.00000 10 5.45599 osd.10 up 1.00000 1.00000 11 5.45599 osd.11 up 1.00000 1.00000 12 5.45599 osd.12 up 1.00000 1.00000 13 5.45599 osd.13 up 1.00000 1.00000 14 5.45599 osd.14 up 1.00000 1.00000 15 5.45599 osd.15 up 1.00000 1.00000 16 5.45599 osd.16 up 1.00000 1.00000 17 5.45599 osd.17 up 1.00000 1.00000 -4 49.10500 host ceph03-hdd 18 5.45599 osd.18 up 1.00000 1.00000 19 5.45599 osd.19 up 1.00000 1.00000 20 5.45599 osd.20 up 1.00000 1.00000 21 5.45599 osd.21 up 1.00000 1.00000 22 5.45599 osd.22 up 1.00000 1.00000 23 5.45599 osd.23 up 1.00000 1.00000 24 5.45599 osd.24 up 1.00000 1.00000 25 5.45599 osd.25 up 1.00000 1.00000 26 5.45599 osd.26 up 1.00000 1.00000 -5 49.13992 host ceph04-hdd 27 5.45999 osd.27 up 1.00000 1.00000 28 5.45999 osd.28 up 1.00000 1.00000 29 5.45999 osd.29 up 1.00000 1.00000 30 5.45999 osd.30 up 1.00000 1.00000 31 5.45999 osd.31 up 1.00000 1.00000 32 5.45999 osd.32 up 1.00000 1.00000 33 5.45999 osd.33 up 1.00000 1.00000 34 5.45999 osd.34 up 1.00000 1.00000 35 5.45999 osd.35 up 1.00000 1.00000 -6 49.13992 host ceph05-hdd 36 5.45999 osd.36 up 1.00000 1.00000 37 5.45999 osd.37 up 1.00000 1.00000 38 5.45999 osd.38 up 1.00000 1.00000 39 5.45999 osd.39 up 1.00000 1.00000 40 5.45999 osd.40 up 1.00000 1.00000 41 5.45999 osd.41 up 1.00000 1.00000 42 5.45999 osd.42 up 1.00000 1.00000 43 5.45999 osd.43 up 1.00000 1.00000 44 5.45999 osd.44 up 1.00000 1.00000 |
Bu örnekte 5 adet Ceph OSD sunucusunda hem SSD tipinde hem de NL-SAS tipinde diskler bulunmaktadır. Bu diskler farklı yaprak (leaf) düğümler şeklinde tanımlanıp ilgili sunuculara eklenmiştir.
Ayrıca tanımlanan kurallar da aşağıdaki gibidir:
|
1 2 3 4 5 |
# ceph osd crush rule list [ "hdds", "ssds" ] |
Buradaki kuralların CRUSH map içindeki kök (root) düğümler olduğu dikkatten kaçmamalıdır. Bu kuralların detaylarına bakıldığında ise birisinin kimliğinin 0, diğerinin 1 olduğu görülecektir.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# ceph osd crush rule dump hdds { "rule_id": 0, "rule_name": "hdds", "ruleset": 0, "type": 1, "min_size": 1, "max_size": 10, "steps": [ { "op": "take", "item": -1, "item_name": "hdds" }, { "op": "chooseleaf_firstn", "num": 0, "type": "host" }, { "op": "emit" } ] } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# ceph osd crush rule dump ssds { "rule_id": 1, "rule_name": "ssds", "ruleset": 1, "type": 1, "min_size": 1, "max_size": 10, "steps": [ { "op": "take", "item": -7, "item_name": "ssds" }, { "op": "chooseleaf_firstn", "num": 0, "type": "host" }, { "op": "emit" } ] } |
Herhangi bir veri havuzunun ilgili disk grubunu kullanması için bir atama yapılması gerekmektedir. Şimdi her biri 100 PG’den oluşan bench_hdd ve bench_ssd isimli veri havuzlarını oluşturarak birisini SSD diskleri, diğerini NL-SAS diskleri kullanacak şekilde ayarlayalım.
|
1 2 3 4 |
#ceph osd pool create bench_hdd 100 100 #ceph osd pool set bench_hdd crush_ruleset 0 #ceph osd pool create bench_ssd 100 100 #ceph osd pool set bench_ssd crush_ruleset 1 |
İlgili kural setlerine yapılan atama ile artık bu veri havuzları oluşturulan bu disk gruplarını kullanacaktır. Yani bench_hdd veri havuzu kural 0 ile belirtilen ve “hdds” isimli kök düğüm altında kalan tüm sunuculardaki OSD’leri kullanacak, bench_ssd veri havuzu ise kural 1 ile belirtilen ve “ssds” isimli kök düğüm altında kalan tüm sunuculardaki OSD’leri kullanacaktır.
Bu yazıda kısaca Ceph mimarisi ve Ceph üzerinde verinin nasıl konumlandırıldığı açıklanmıştır.
Ceph ile ilgili gelişmelerden ve etkinliklerden haberdar olmak için yeni meetup grubumuza kayıt olun.

Bir sonraki yazıda Ceph tasarımında dikkat edilmesi gereken hususlardan bahsedeceğim. Takipte kalın ! (Stay tuned)
Elinize sağlık. Özellikle verinin nasıl yerleştirilmesine dair aklımdaki soru işaretlerine açıklık getirdiniz.
Teşekkürler